Data Virtualization as the Powerhouse for Transaction Reporting
Erik te Selle
Senior Manager, Synechron,The Netherlands
Tim Seta
Senior Consultant, Synechron,The Netherlands
Data
Examining the bigger picture Is your organization struggling with becoming regulatory compliant by changing the simplest data element in your Transaction Reporting process? A proper review of the overall architecture could be the best way to go. And with a technology-like Data Virtualization, there is a solution path to simplify and improve your Transaction Reporting architecture. In this article we focus on the architecture involved with Transaction Reporting.
Organizations need to start thinking about improving their current Transaction Reporting processes. This includes conducting a thorough assessment of the involved architecture -- if not for reasons of efficiency and cost improvement, then for the increased regulatory focus on quality and correctness. In this article, the concepts of Data Lakes and Data Virtualization are introduced and their relevance for Transaction Reporting processes is discussed.
Defining the problem
Over the past several years, demanding regulatory deadlines were chased. This drove the implementation of Transaction Reporting in the processes and systems of companies and resulted in an architecture that was, or still is, not meeting the demands of the future.
Within a generic Transaction Reporting processes framework, as depicted below, the ingestion of data in the reporting engine is likely not as straight forward as portrayed. It is common to see over a dozen different systems interfaced, with hundreds of data points being bounced back and forth between the systems. Some key challenges can be identified which are summarized in our previous article
The Generic Transaction Reporting Processes Framework
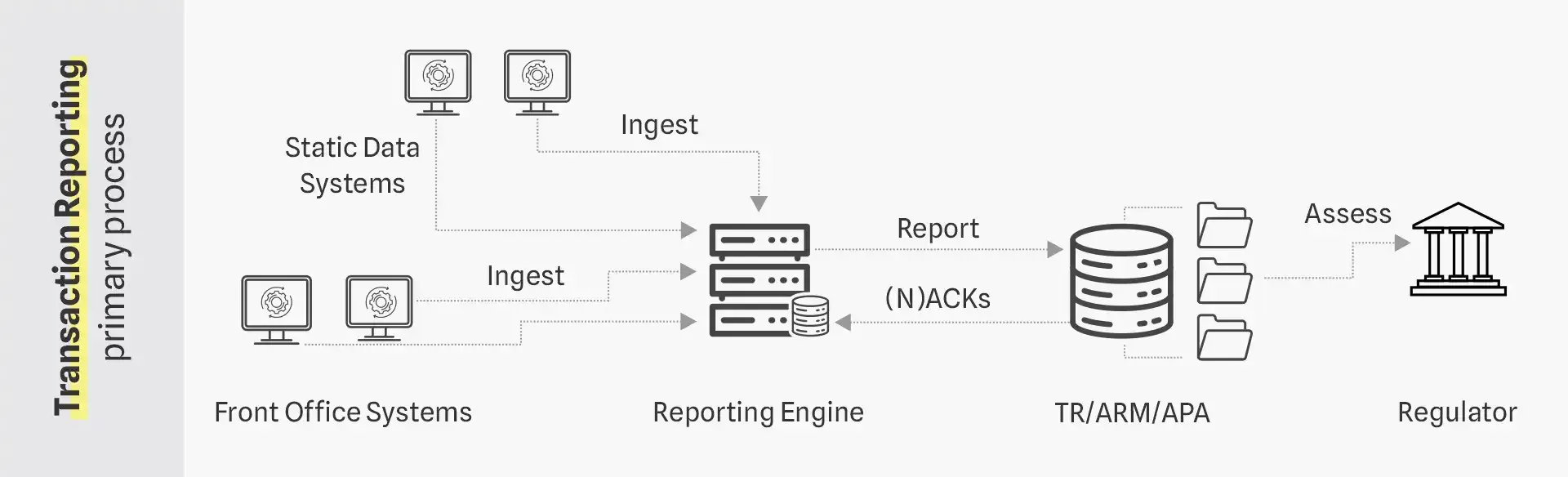
Focusing on the core architecture, there are multiple elements likely at the root of Transaction Reporting issues, like data quality, an abundance of data formats, almost endless point-to-point interfaces, and source system deficiencies. The architecture and systems involved are not often designed or even equipped for the standards and requirements dictated by Transaction Reporting (e.g., near-real-time reporting, data availability requirements, and data transformation requirements).
Additionally, running a complex architecture often results in quite a burden with regards to maintenance and managing changes (e.g., system and data, file formats, and interfaces). Moreover, there are more stringent expectations and regulations on the topic of data ownership and accountability in which a solid architecture plays a vital role.
How technology can help
The aforementioned key challenges can be addressed by introducing a Data Lake to improve the architecture supporting Transaction Reporting processes. Data Lakes will provide tangible benefits which we will investigate here. However, over the past few years Data Lakes have presented some shortcomings which we want to highlight as well.
In recent years, Data Virtualization has evolved into the technology that could potentially be a more future fit solution. Here, we will introduce the concepts of Data Lakes and Data Virtualization along with their benefits and shortcomings.
Understanding Data Lakes A Data Lake is a centralized repository that allows organizations to store all structured and unstructured data at any scale.
Although often used interchangeably with a Data Warehouse, a Data Lake is fundamentally different. Unlike a Data Warehouse, a Data Lake retains all data and does not apply any transformation to the data. This means that data is stored in the rawest form possible. In essence, (financial) companies export all data from their core systems in a central database to be used for other processes like specific reporting and Management Information. This early ingestion (and late processing) of data is a key characteristic of Data Lakes and enables organizations to leverage important benefits, including the following:
- Reduces up-front effort: The raw storage of data reduces up-front effort, as no initial data modelling is required.
- Lowers cost: Storage of the data is therefore low cost, which allows organizations to collect and store a wide range of data without a predefined purpose and be useful for data analysts and data scientists to perform analyses and discover deeper insights.
- Connect multiple sources: With a Data Lake, many different sources (internal and external) can be connected to ingest data in different frequencies.
When there is a clear business purpose defined (e.g., Transaction Reporting), and the Data Lake is prepared accordingly, data can be further processed to enable the creation of a specific output/report.
The concept of merging all data sources into a centralized repository (i.e., Data Lake) also brings some challenges for organizations, in particular:
- Space Limitations: Space constraints are more likely to occur due to the storage of large amounts of data and data duplication.
- Increased risk: High risk for data inconsistencies, as constant synchronization between the original data source and the Data Lake is needed; the data is only as current as the last sync point.
- Governance challenge: Data governance/ownership problems can occur due to the data sharing model of Data Lakes, which can make users tempted to just ‘dump’ data in the lake and not take further ownership of it. This will lead to:
- Direct challenges with adhering to regulations, for example GDPR (2018) and BSCBS239 (2013).
- Risks of creating a data swamp (i.e., an unmanaged Data Lake that is either inaccessible to intended users or provides little value).
- Poor data quality in source systems leading to inefficient processes and inaccurate reports.
Data Lakes, however, bring important benefits regarding data storage, analysis and scalability. But the challenges outlined above are causes for serious concern, if not properly addressed. An approach that dismisses these challenges altogether, is Data Virtualization.
Understanding Data Virtualization Data Virtualization integrates different types of data from multiple sources into a holistic, logical view without moving it physically.
The concept of Data Virtualization is as old as Data Lakes, but back in 2010 the capacity and performance needed for Data Virtualization could not match the requirements to make the concept function effectively. However, with the introduction of Microservices in 2010 (with Amazon and Netflix as the pioneers), network and processor speeds have literally become a million times faster. Additionally, improved communication protocols have been tested and commercialized for large data transfers and long messaging queues. Essentially, the technology is now supporting the demanding requirements of Data Virtualization, making it the best solution path to consider.
With Data Virtualization, users can access data directly from the golden source, across multiple data types, locations, or formats, without having to do any data duplication or moving of data. Accessing data from the golden source directly addresses the shortcomings of Data Lakes and marks the following benefits of Data Virtualization:
- Banishing data duplication: No more data duplication, leading to space and cost savings for organizations.
- Always current data: Data is always up-to-date and accurate, which prevents inconsistencies in different systems.
- Ensuring control/ownership: Offers the ability to enforce proper control and ownership over data, as it only resides in the systems of a particular domain. This allows organizations to focus resources on building governance and establishing proper control over data within the specific domains, as well as facilitating regulatory compliance in accordance with BCBS239 and GDPR.
On the other hand, there are certain challenges with Data Virtualization as well, including:
- Greater setup costs: The initial setup costs of servers and storage is higher than of a regular server setup.
- Scalability Issues: Quick scalability is more challenging due to the need for requisite software, security, enough storage, and resources.
- Time investment: There may be some risks of dips in performance, leading to higher time required to complete tasks, since resources in virtualization are shared between users.
Side-by-side comparison Comparing both technologies, conventional Data Lakes are still needed to do some of the heavy lifting of big data operations (e.g., storage and data analysis). However, Data Virtualization directly addresses the shortcomings of Data Lakes. Data Virtualization also leverages key benefits with respect to data sourcing as well as governance and ownership of data, on top of making the day-to-day operational data more accessible with low time-to-market to the business users. These are important considerations for organizations and could improve many business processes, including Transaction Reporting.
Data Virtualization as the powerhouse for Transaction Reporting
When assessing the Transaction Reporting processes framework (see diagram above), its key challenges, and the technology involved, it is obvious that a critical look at the architecture could greatly benefit organizations. With the introduction of Data Virtualization specifically, organizations are able to leverage some key benefits:
- The technology will increase the governance, control, and ownership of the data.
- The data is operationally ready and sourced without duplication from a golden source.
- There will be increased compliance to regulations (e.g., GDPR and BCBS).
Transaction Reporting would be able to leverage these key benefits of Data Virtualization. The immediate effect would be the following:
- A clear delineation between data ownership and ownership of the business rules. This will improve the transparency throughout the value chain on the topic of data requirements.
- A clear impact on the compliancy rate of the reports. The data is sourced directly from the golden source, and the Transaction Reporting business rules and transformations are governed separately.
- The controls on the process of Transaction Reporting are more easily implemented and more transparent as the data is maintained in its original source.
- The maintenance and support of the architecture will become less complex and costly.
Extended benefits of Data Virtualization
Transaction Reporting is not the only business process that uses the source data, which means Data Virtualization will have side benefits as well:
- Other business processes that can benefit from this technology include finance, risk, and reconciliations.
- The improved governance and control will increase the steering capabilities of an organization as the data quality of Management Information will improve.
- An increased agility in the world of constantly changing (regulatory) requirements as the architecture is simplified and more easily to maintain and adapt.
Conclusion:
Data Virtualization has the potential to be a powerhouse in the architecture of Transaction Reporting.
For more information on Transaction Reporting data quality requirements, please read this article published by Synechron: https://www.synechron.com/insights/adhering-transaction-reporting-data-quality-requirements
What can Synechron offer in Transaction Reporting? Synechron has, on multiple occasions, been tasked with setting up and improving Transaction Reporting processes for our financial services industry clients. This provides us with an excellent understanding and vision of the most relevant pain points and improvements needed to ensure a proper Transaction Reporting implementation -- from the regulation all the way to system implementation. This includes control frameworks and creating data hubs. With our industry-focused regulatory domain knowledge, hands-on change specialists and technology leadership, we are uniquely positioned to assist you in any capacity -- from analysis to implementation, and program management to development.
Want further, in-depth information and insight about our capabilities and vision on Transaction Reporting?
Connect with us and let’s talk:
The Author

Erik te Selle
Senior Manager, Synechron
Checkout our new website: Transaction Reporting
Interested in joining our Digital Transformation journey? At Synechron, we believe in the power of digital to transform businesses for the better. Our global consulting firm combines creativity and innovative technology to deliver industry-leading digital solutions. Synechron’s progressive technologies and optimization strategies span end-to-end Consulting, Design, Cloud, Data and Engineering, servicing an array of noteworthy financial services and technology firms. Through research and development initiatives in our Synechron Labs we develop solutions for modernization, from Blockchain and Artificial Intelligence to Data Science models, Digital Underwriting, mobile-first applications and more. Over the last 20+ years, our company has been honored with multiple employer awards, recognizing our commitment to our talented teams. With top clients to boast about, Synechron has a global workforce of 14,000+, and has 40 offices in 17 countries within key global markets.
Check out the current vacancies on our website: Careers
Reach out to: erik.teselle@synechron.com
See more about him here: linkedin