AI Hallucinations: Why Bots Make Up Information
Prabhakar Srinivasan
Co-Head of AI,Bangalore
Anupama Sharma
Intern,Bangalore
AI
Large language models (LLMs) power the Generative AI capabilities in artificial intelligence (AI), excelling at tasks like generating text, translating languages, and answering questions, to name a few. However, a critical issue lurks beneath the surface which is their tendency to create content that may be factually incorrect or even nonsensical. This phenomenon is often referred to as “hallucination”. Cognitive scientists refer to this phenomenon as “confabulation” to more accurately describe this specific challenge within AI.
All GenAI LLMs, without exception, are susceptible to hallucinations, albeit to varying degrees. According to Vectara’s hallucination leaderboard for LLMs GPT4-Turbo currently leads with the lowest reported hallucination rate at 2.5%. In contrast, Anthropic’s Claude 3 Opus exhibits a significantly higher rate of 7.4%. This variability underscores the challenge of mitigating hallucinations and the critical need for ongoing advancements in AI technology to enhance accuracy and reliability.
The consequences of hallucination in LLMs can be significant. Consider the case of an AI chatbot for customer support. Hallucination can render the chatbot hard to interact with, causing frustration for the customer during the interactions, drifting into profanity, poor humor, and even self-deprecating poetry. Hallucinations in LLMs may generate misleading or offensive content, compromising system reliability, jeopardizing user trust, and impacting brand image.
Understanding the nuances of hallucinations in large language models is crucial for advancing their reliability.
As outlined in the published paper "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions," we can categorize these errors into two primary types:
1. Factuality hallucinations: These occur when models generate outputs that either contradict verified facts or fabricate details. They further break down into:
- Factual inconsistency: For instance, incorrectly stating the year of the moon landing as 1975.
- Factual fabrication: For example, falsely claiming the origin of the tooth fairy as New York.
2. Faithfulness hallucinations: This category involves responses that do not adhere to the user's instructions or the provided context, leading to logical discrepancies. Types include:
- Instruction inconsistency: Such as misinterpreting a request to translate "What is the currency of SA?" into French, but instead responding with the currency of the USA.
- Context inconsistency: Misrepresenting the Himalayas as spanning South African nations instead of South Asian ones.
- Logical inconsistency: Incorrectly identifying the second prime number as 2, despite the definition of a prime number.
But why does this happen?
Hallucination in large language models can be traced back to three main sources.
- Data-driven issues: The foundation of any LLM is the data it's trained on. When this data is flawed, whether due to mismatches between training data and task requirements or simply poor data quality, the model may lose its factual grounding. Additionally, training on a vast corpus that includes biases or inconsistent information can embed these inaccuracies into the model, leading it to replicate these errors and biases in its outputs.
- Training-driven issues: The training methodologies themselves can also introduce hallucinations. Limitations in model architecture, such as flaws in transformer structures used for learning, can restrict a model’s ability to generate accurate predictions. Furthermore, training objectives that don’t align with real-world use — such as reliance on autoregressive predictions — can exacerbate the risk of hallucinations by lowering the mathematical probability of the model remaining within the bounds of correct responses.
- Inference-driven issues: During the inference stage, the actual generation of text, certain inherent limitations become apparent. Techniques intended to enhance diversity and creativity in responses can instead introduce randomness, leading to nonsensical or misleading outputs. Additionally, the decoding mechanisms may focus too narrowly on recent inputs or suffer from constraints like the SoftMax bottleneck, which can distort the model’s output away from accurate or relevant answers.
Traditional metrics based on word overlap struggle to discern between plausible content and hallucinations, underlining the need for advanced detection techniques.
These methods can be grouped into detecting factuality and faithfulness hallucinations. See the diagram below:
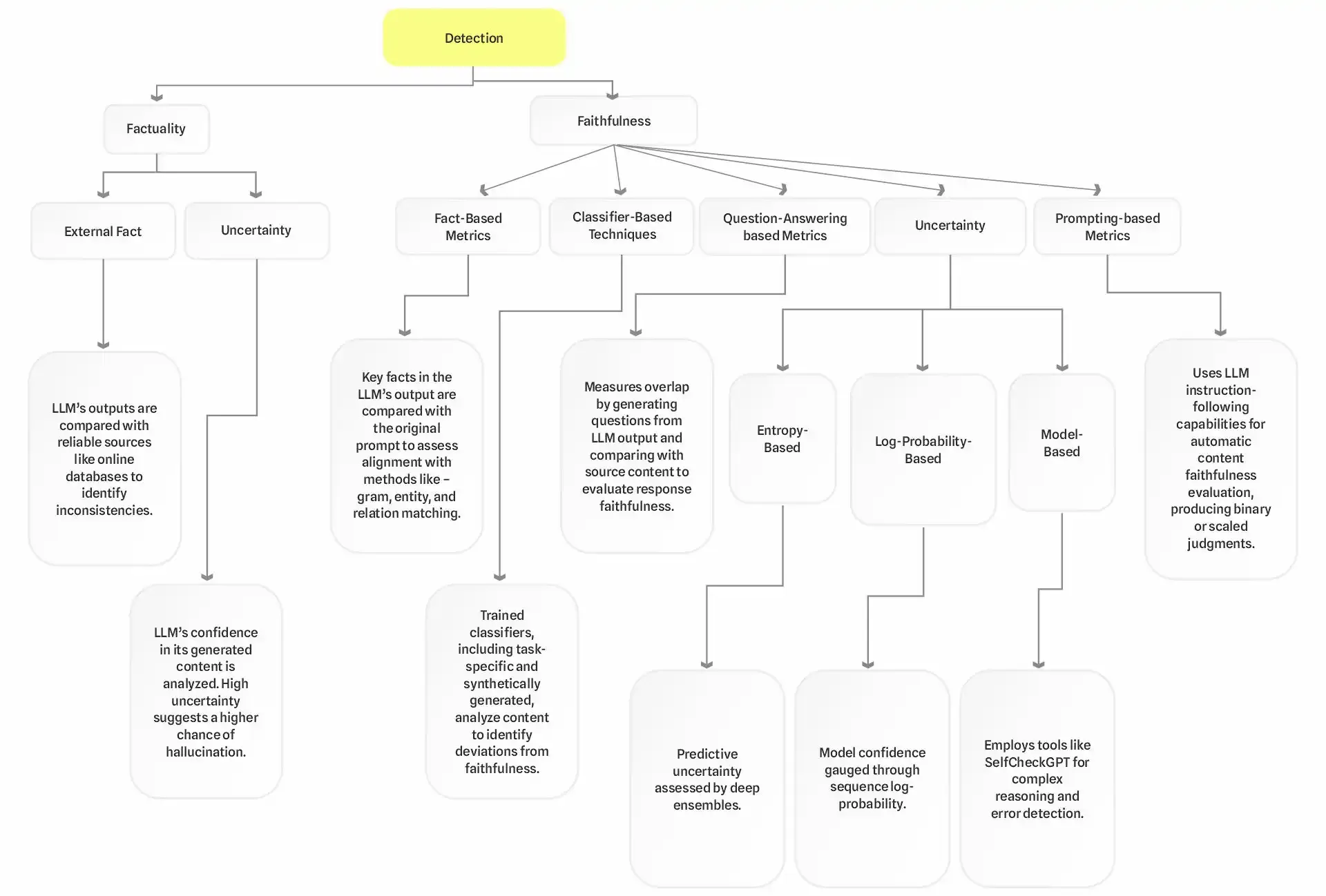
Researchers are continually refining methods to assess the reliability of large language models (LLMs), specifically focusing on their ability to produce truthful and accurate responses.
These assessments fall into two main categories.
1. Evaluation benchmarks: These tools are designed to gauge the propensity of LLMs to hallucinate by measuring their factual accuracy and their ability to adhere to the given context. For instance:
- TruthfulQA presents LLMs with intricately devised questions that aim to reveal their factual inaccuracies.
- REALTIMEQA evaluates LLMs using questions based on current events, testing their ability to provide timely and accurate information.
- Med-HALT is tailored for the medical field, assessing LLMs on their reasoning and memorization capabilities within medical contexts.
2. Detection benchmarks: These benchmarks are crucial for testing how effectively LLMs can detect and mitigate their own hallucinations. Notable examples include:
- SelfCheckGPT-Wikibio scrutinizes sentence-level hallucinations in Wikipedia articles generated by GPT-3, focusing on the accuracy of generated content.
- HaluEval employs a combination of human evaluation and automated techniques to assess LLMs across various prompts, helping to identify discrepancies in their outputs.
- FELM specifically tests ChatGPT’s proficiency in discerning factual information across diverse domains, highlighting its capability to detect and correct its own errors.
Researchers, of course, continue to explore ways to combat hallucinations in LLMs, but it's not that simple. In the meantime, users can manage LLM outputs more effectively with simple, practical strategies.
Craft clear and specific prompts that guide the model towards generating the desired information accurately. This minimizes misunderstandings and reduces the chances of irrelevant or incorrect responses. Follow up with targeted questions to refine the output, ensuring the responses adhere closely to factual accuracy and relevance. Regularly verify the information provided by the model against trusted sources, especially when using outputs for critical applications.
After all, AI should be used to complement and enhance your human creativity, leveraging its capabilities to expand possibilities and to innovate effectively.
The Author

Prabhakar Srinivasan
Co-Head of AI
Prabhakar, based in Bangalore, India, is a seasoned professional with over a decade of experience in the field of AI, ML and Data Science. Currently the Co-Head of Synechron’s AI Practice, he and his team work on the research and development of cutting-edge Generative AI, Computer Vision, Advanced NLP, Deep Learning and Recommender Systems. Prior to joining Synechron, Prabhakar worked as a Data Scientist and Software Engineer at large enterprises including Apple, CISCO, Yahoo & Samsung. Prabhakar has a Master’s in Computer Science from DePaul University, Chicago and a Masters in Software Systems from BITS Pilani, India.

Anupama Sharma
Intern
Anupama is based in Bangalore and will graduate in July 2024 from the BITS Pilani KK Birla, Goa campus. She is currently an intern under the mentorship of Prabhakar Srinivasan.